将 PDF 表格转换为可编辑的 Word 表格:精确转换方法详解
将 PDF 表格转换为可编辑的 Word 表格:精确转换方法详解
将 PDF 表格转换为 Word 表格看似简单,但实际操作往往不尽如人意。由于 PDF 的设计目标是“展示”而不是“编辑”,转换过程中经常出现各种问题:表格结构错乱、行列拆分异常、边框丢失、单元格对不齐,甚至直接被导出为无法编辑的图片。
这篇完整指南将为你介绍几种可靠方法:包括在线转换、桌面软件处理,以及精确度最高的程序自动化提取方式。无论你是需要快速转换 PDF 表格,还是要提取结构化 PDF 表格数据用于自动化流程,本文都能提供实用的方法与技术参考。
1. 为什么 PDF 表格转换为 Word 会很困难?
在选择转换方法之前,有必要了解 PDF 表格难以识别的原因,这能帮助你判断哪种工具更适合你的文档结构。
1.1 PDF 并不真正包含“表格”
与 Word 或 HTML 不同,PDF 不会存储结构化的 <table> 元素,它的内部结构通常是:
- 文本按绝对坐标定位
- 表格线条以绘图路径呈现
- 行列只是视觉对齐,不是实际的单元格结构
因此:
- 转换工具无法直接区分哪些是单元格
- 线条未必代表真实边界
- 复制或导出时经常破坏布局
这也是为什么“复制粘贴”几乎不可能得到干净表格的原因。
1.2 Word 需要真实结构化的表格数据
Word 期望的表格必须包含:
- 明确的
<table>结构 - 一致的行列数量
- 真实的单元格与边界
- 可调节的列宽
如果 PDF 无法被解析成这样的结构,Word 通常会生成不可预期的结果,甚至直接将表格以图片方式导出。
这也解释了为何高质量的 PDF 表格提取 需要复杂的解析过程,而不只是简单地视觉转换。
2. 可行方法总览
本文介绍三种常见且可靠的转换方式:
- 在线 PDF 转 Word —— 最快、无须安装
- 桌面软件转换 —— 稳定性更高、精度更好
- 程序化提取 + Word 表格构建 —— 精准度最高、可自动化处理
小提示:除了代码方式,大多数工具都会把整份 PDF 转为 Word。如果你只需要表格,可能需要手动删除其他内容。
其中最准确的方法是“代码提取 + 重建 Word 表格”,因为它可以最大程度保留结构并确保完全可编辑。
3. 方法一:使用在线工具将 PDF 转换为 Word(最快速)
在线转换是应对简单需求的最快方式,它们会自动检测表格并导出 Word 文档。
使用流程
- 打开在线转换网站(例如 PDF24 Tools)。
- 上传 PDF 文件
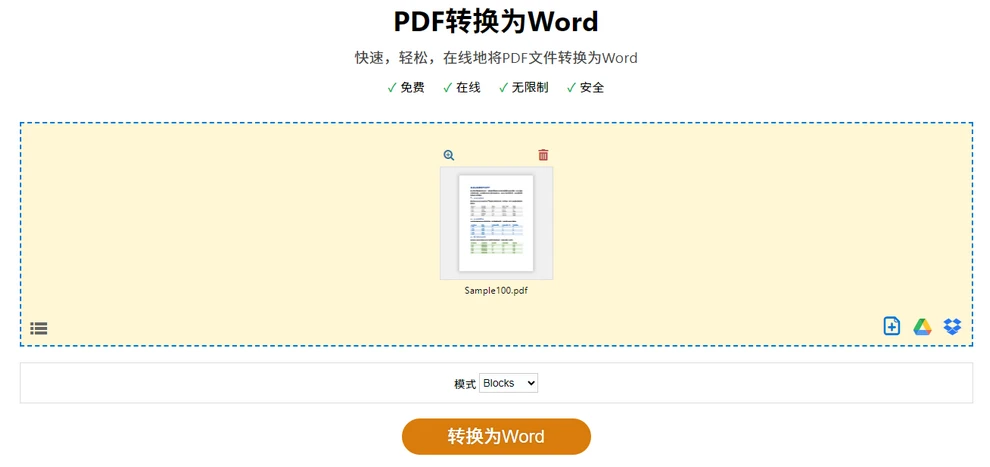
点击转换并等待转换完成
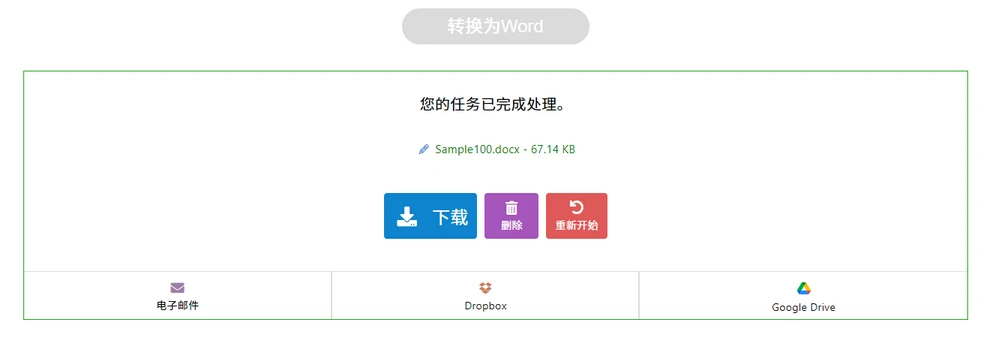
下载生成的 Word 文件

必要时在 Word 中微调格式
优点
- 无需安装软件
- 任意设备可使用
- 转换速度快
缺点
- 复杂表格精度较低
- 需要上传文件,存在隐私风险
- 某些表格会被当作图片导出
- 自定义能力有限
在线工具适合简单、一次性需求。
4. 方法二:使用桌面软件转换 PDF 为 Word(更稳定、更安全)
桌面软件在本地处理文档,通常比在线工具解析更精准且无隐私风险。常用软件包括 Microsoft Word、Acrobat 及其他 PDF 工具。
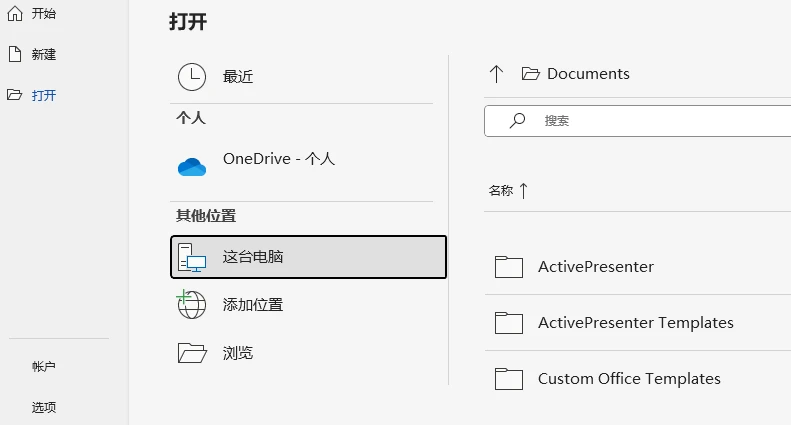
通用操作流程
安装软件,例如 Microsoft Word
在软件中打开 PDF 文件
确认转换
等待处理完成
将结果保存为 .docx
优点
- 表格检测更准确
- 适合大文件、多页文档
- 文件不上传服务器,更安全
缺点
- 某些软件需要付费
- 对复杂表格仍可能解析出错
- 各软件处理效果差异较大
适用于中等复杂度的 PDF 表格。
5. 方法三:使用 Python 自动化提取与转换 PDF 表格为 Word(精确度最高)
如果你需要 稳定、自动化且高度可控的转换结果,程序化方式是最佳选择。
它支持:
- 精确提取表格内容
- 完全控制 Word 表格结构
- 批量处理
- 一致、可预测的格式
甚至在复杂、不规则表格中也能重建出干净、完全可编辑的 Word 表格。
5.1 方案 A:自动将整份 PDF 转为 Word
使用 Free Spire.PDF for Python 可以直接将 PDF 转为 Word,软件将通过分析线条、文本定位等方式推测表格结构。
通过 pip 安装 Free Spire.PDF for Python:
1 | pip install spire.pdf.free |
Python 示例代码:PDF → Word
1 | from spire.pdf import PdfDocument, FileFormat |
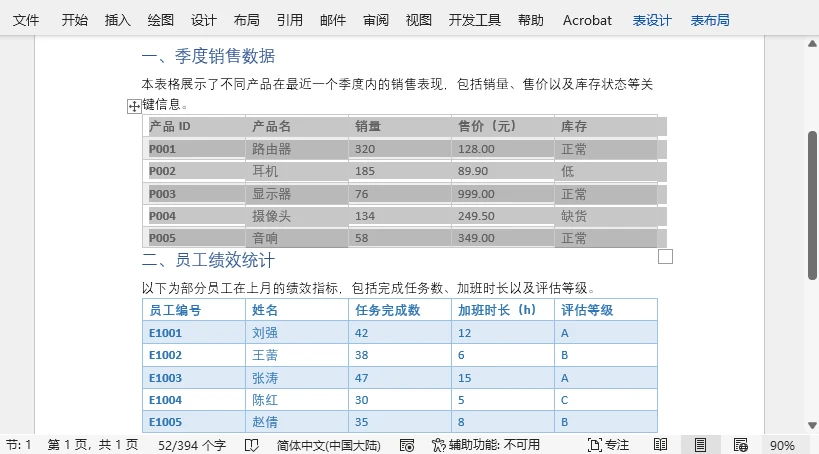
转换效果示例:
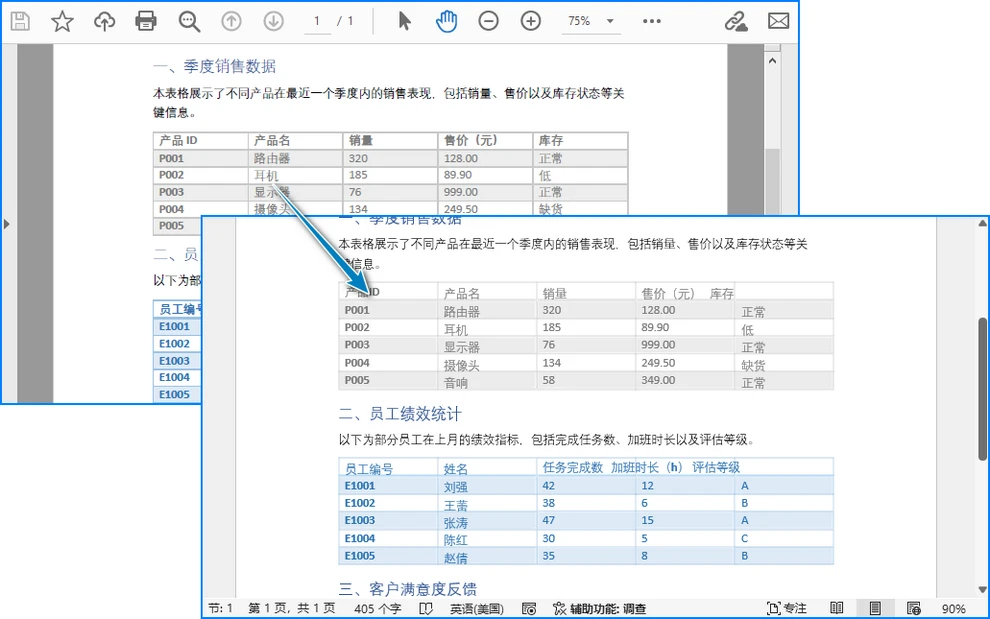
适用场景
- 表格结构清晰、带线框
- PDF 布局规则
- 对精确度要求不是极高时
限制
- 复杂合并单元格可能失真
- 无边框表格可能识别不准
如果你需要在转换过程中进行更多参数控制,请查看 如何使用 Python 转换 PDF 为 Word。
5.2 方案 B:提取 PDF 表格数据并在 Word 中重建(精度最高)
使用 Free Spire.PDF for Python + Free Spire.Doc for Python,可以实现:
- 提取真实表格数据
- 完全重建 Word 表格
- 全可编辑
- 可完全控制格式与样式
- 适合自动化流程
通过 pip 安装 Free Spire.Doc for Python:
1 | pip install spire.doc.free |
工作流程
- 从 PDF 中识别并提取表格
- 创建 Word 文档
- 根据提取的数据构建 Word 表格
- 添加样式与格式
Python 示例:提取 PDF 表格 + 生成 Word 表格
1 | from spire.pdf import PdfDocument, PdfTableExtractor |
效果示例:
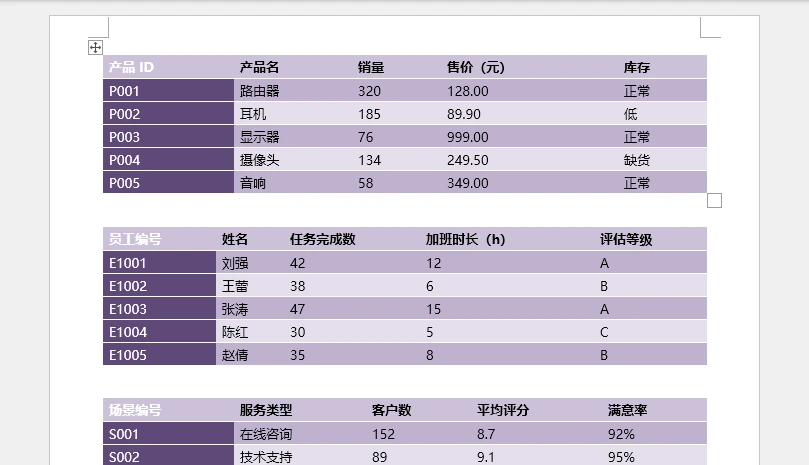
为什么这是最佳方案?
- 表格始终为可编辑格式
- 高度适合自动化和批量处理
- 无需依赖 PDF 的边框、线条
- 可完全控制字体、边框、样式
适用于专业场景和企业级处理流程。
你还可以通过 Free Spire.PDF for Python 提取 PDF 文档表格数据并保存到更多格式,参考 如何使用 Python 提取 PDF 表格数据。
6. 准确度对比
| 方法 | 准确度 | 可编辑性 | 格式控制 | 适用场景 |
|---|---|---|---|---|
| 在线工具 | ★★★★☆ | 是 | 低 | 简单场景、快速处理 |
| 桌面软件 | ★★★★☆ | 是 | 中 | 普通文档 |
| 程序化提取 + 重建 | ★★★★★ | 是 | 完全可控 | 自动化、复杂表格 |
| 整份 PDF → Word 自动转换 | ★★★★☆ | 是 | 中 | 结构清晰的 PDF |
7. 提高转换质量的最佳实践
文件准备
- 优先使用可复制文本的 PDF
- 扫描版文件需先 OCR 识别
表格设计建议
- 列对齐尽可能一致
- 少用不必要的合并单元格
- 列与列之间保持适当间隔
技术建议
- 批量流程建议使用代码方案
- 为保持格式,推荐重建 Word 表格
- 转换后应检查数据完整性
8. 常见问题解答
1. 如何在不破坏格式的情况下将 PDF 表格转为 Word 可编辑表格?
优先使用高质量桌面软件或 Spire.PDF + Spire.Doc 的程序化方案。
2. 可以只把 PDF 中的表格提取到 Word 吗?
可以。通过程序化方法提取表格并在 Word 中重建,是最可靠的方式。
3. 为什么我的 PDF 表格在 Word 中变成了图片?
转换器没有识别出表格结构,只能将其作为图片处理。建议使用支持表格重建的工具。
4. 对复杂、非常规的表格,哪种方法最准确?
程序化提取 + 手动构建 Word 表格。
9. 总结
PDF 表格转换为 Word的难度取决于 PDF 的结构复杂程度。在线工具和桌面软件适用于简单布局,但面对合并单元格、不规则间距或多行结构时,往往难以保持准确性。
对于需要高精度、可编辑、可自动化的专业用户来说,程序化提取是最佳选择。它提供最高级别的控制能力,能够在 Word 中重建精准、干净的表格结构。
无论你需要快速转换,还是构建稳定、可扩展的自动化流程,本文介绍的方法都能帮助你高质量地将 PDF 表格转换为可编辑的 Word 表格。